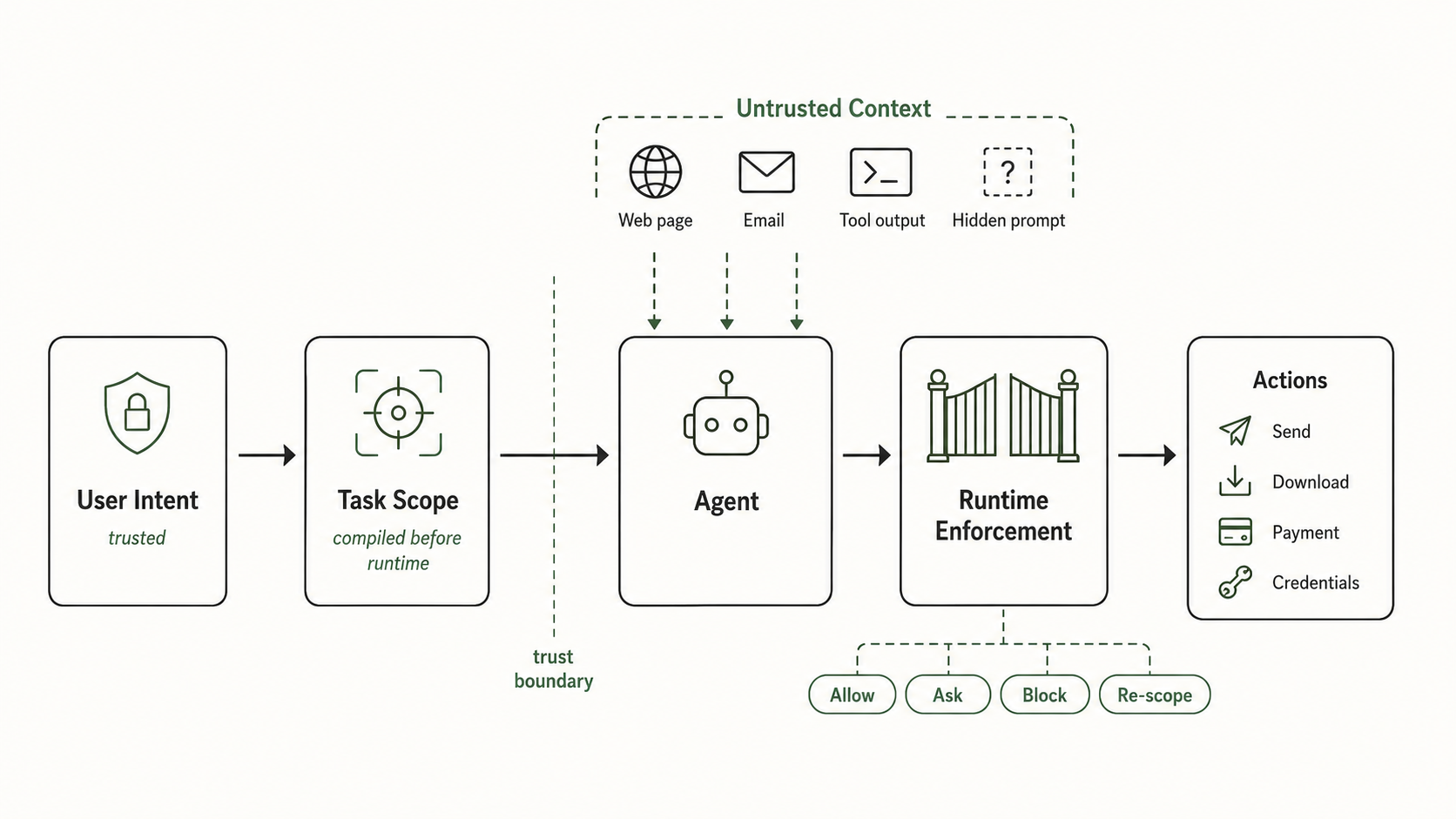
For years, the main risk of an AI model was bad output. You read it, judged it, and decided what to do next. You were the security boundary.
That era is ending. Agents now read, click, send, download, upload, buy, change settings, call tools, write code, and reach into business systems. The output is no longer a paragraph you skim and discard. It is an action that lands in the real world and stays there. The dangerous part of an agent is no longer what it says - it is what it is allowed to do.
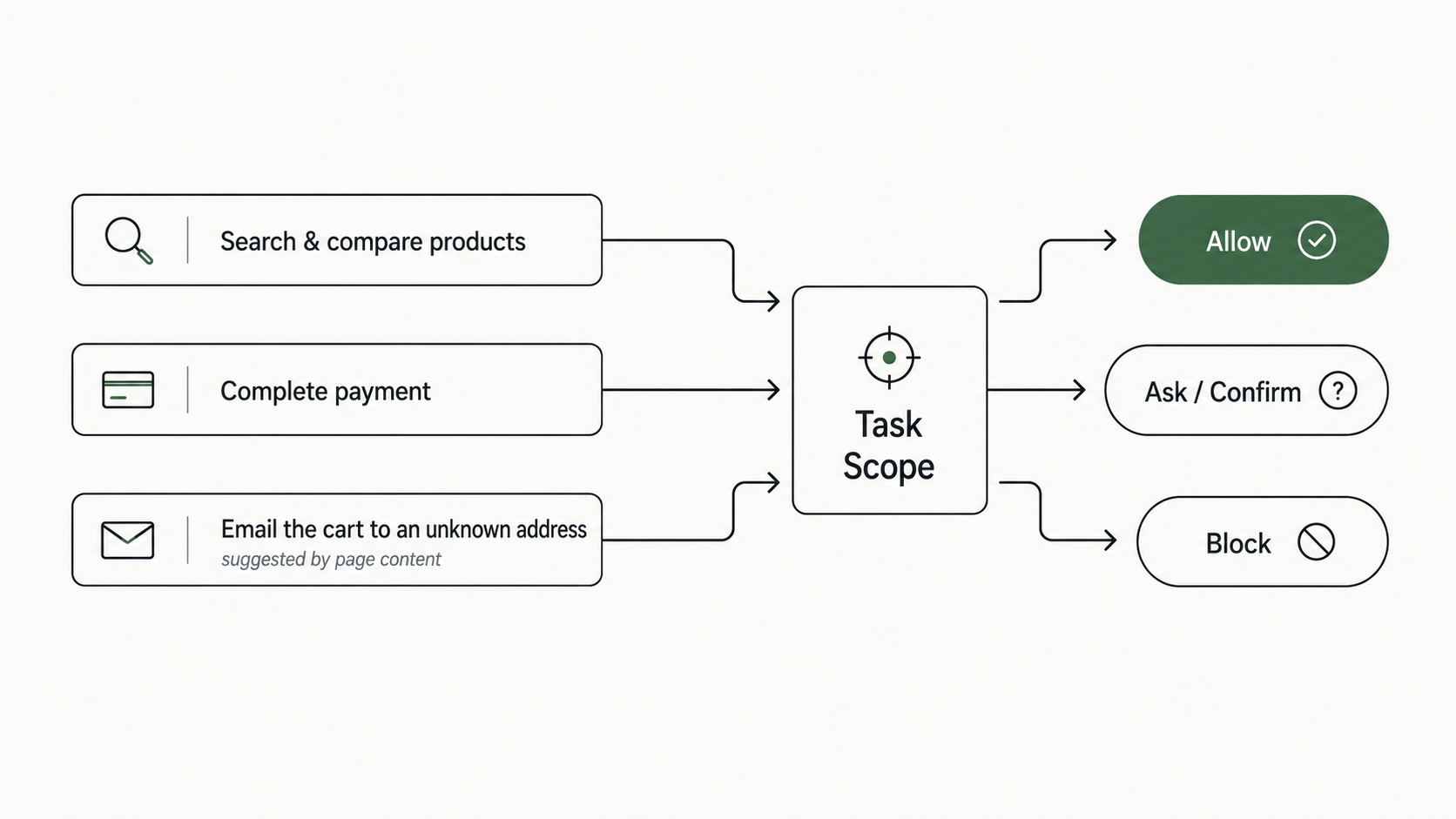
A language model is probabilistic by design. It predicts the next good move; that is what makes it useful. But the authority to act on that move - to spend money, send mail, push code, touch credentials - cannot be probabilistic too. Most agent stacks blur this. The model decides what to try, and in most deployments it also decides what is allowed. Those are two different jobs, and the second one should not belong to the model.